


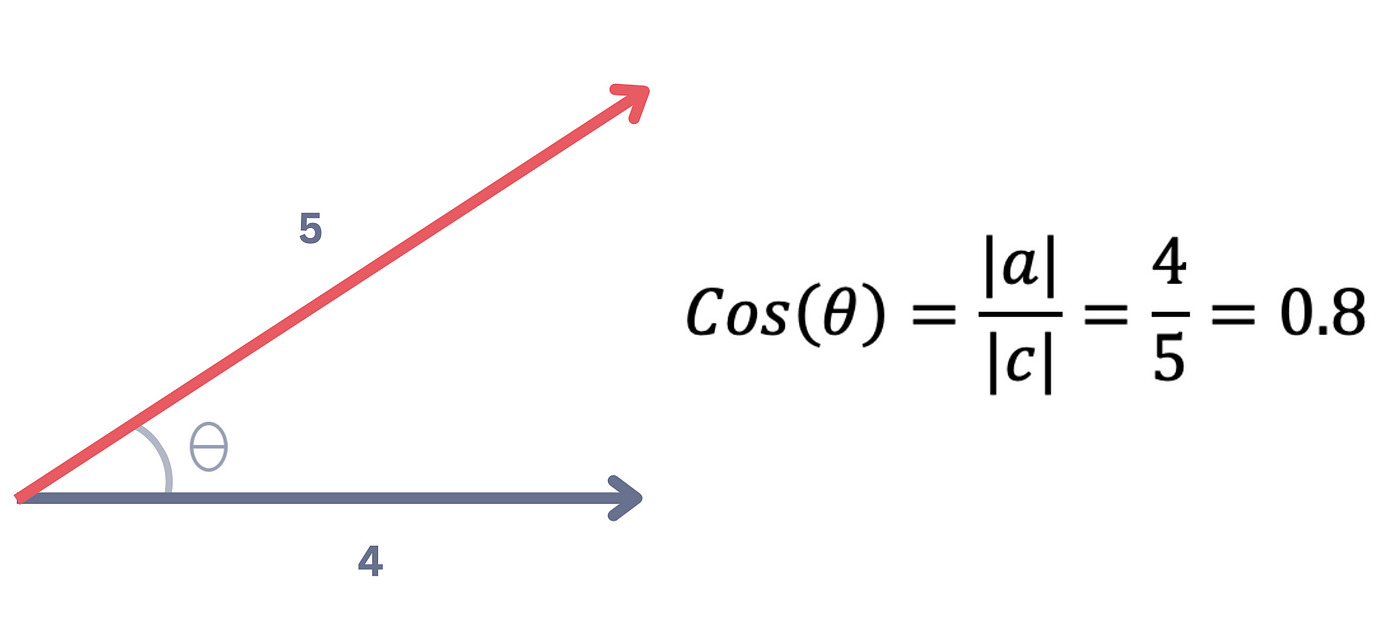
Cosine similarity is a powerful tool in the world of data science and machine learning. But what exactly is it? Cosine similarity measures the cosine of the angle between two non-zero vectors in a multi-dimensional space. This metric helps determine how similar two vectors are, regardless of their size. Imagine comparing two documents to see how alike they are based on word frequency. Cosine similarity shines in text analysis, recommendation systems, and clustering tasks. It’s especially useful when dealing with high-dimensional data, where traditional distance metrics might fall short. Ready to dive into the fascinating world of cosine similarity? Let's explore 20 intriguing facts about this essential concept!
What is Cosine Similarity?
Cosine similarity measures the cosine of the angle between two non-zero vectors in a multi-dimensional space. It helps determine how similar two sets of data are.
-
Cosine similarity ranges from -1 to 1. A value of 1 means the vectors are identical, 0 means they are orthogonal (no similarity), and -1 means they are diametrically opposed.
-
Used in text analysis. It helps compare documents by converting text into vectors and measuring the angle between them.
-
Insensitive to magnitude. Cosine similarity focuses on the direction of the vectors, not their length, making it useful for comparing documents of different sizes.
Applications in Machine Learning
Cosine similarity plays a crucial role in various machine learning algorithms, especially those involving text and image data.
-
Common in clustering algorithms. It helps group similar items together by measuring the similarity between data points.
-
Used in recommendation systems. Platforms like Netflix and Amazon use it to suggest items based on user preferences.
-
Helps in classification tasks. It aids in categorizing data into predefined classes by comparing feature vectors.
How Cosine Similarity Works
Understanding the mechanics behind cosine similarity can provide deeper insights into its applications and limitations.
-
Based on dot product. The formula involves the dot product of two vectors divided by the product of their magnitudes.
-
Requires normalization. Vectors need to be normalized to ensure accurate similarity measurements.
-
Efficient computation. It can be computed quickly, even for large datasets, making it suitable for real-time applications.
Advantages of Cosine Similarity
Cosine similarity offers several benefits that make it a popular choice in data analysis and machine learning.
-
Scalability. It can handle large datasets efficiently, making it ideal for big data applications.
-
Robust to noise. It remains effective even when data contains noise or irrelevant features.
-
Easy to interpret. The results are straightforward, with values indicating the degree of similarity between vectors.
Limitations of Cosine Similarity
Despite its advantages, cosine similarity has some limitations that users should be aware of.
-
Ignores magnitude. While this can be an advantage, it may also overlook important information about the data.
-
Not suitable for all data types. It works best with text and image data but may not be effective for other types of data.
-
Sensitive to vector sparsity. Sparse vectors can lead to inaccurate similarity measurements.
Real-World Examples
Cosine similarity is used in various real-world applications, demonstrating its versatility and effectiveness.
-
Spam detection. Email services use it to identify and filter out spam messages by comparing them to known spam vectors.
-
Plagiarism detection. Educational institutions use it to compare student submissions and detect potential plagiarism.
-
Image recognition. It helps identify similar images by comparing feature vectors extracted from images.
Future of Cosine Similarity
As technology advances, the applications and importance of cosine similarity continue to grow.
-
Integration with AI. It will play a significant role in enhancing AI algorithms, particularly in natural language processing and computer vision.
-
Improved accuracy. Ongoing research aims to refine cosine similarity methods, making them even more accurate and reliable.
The Power of Cosine Similarity
Cosine similarity is a powerful tool in data analysis and machine learning. It helps measure the similarity between two non-zero vectors, making it invaluable for tasks like text analysis, recommendation systems, and clustering. By focusing on the angle between vectors rather than their magnitude, cosine similarity provides a robust way to compare different datasets.
Understanding cosine similarity can enhance your ability to work with large datasets and improve the accuracy of your models. Whether you're dealing with text documents, user preferences, or any other type of data, this method offers a straightforward yet effective way to find patterns and relationships.
So next time you're faced with a complex data problem, consider using cosine similarity. It's a simple concept with wide-ranging applications that can make a significant difference in your analytical toolkit.
Was this page helpful?
Our commitment to delivering trustworthy and engaging content is at the heart of what we do. Each fact on our site is contributed by real users like you, bringing a wealth of diverse insights and information. To ensure the highest standards of accuracy and reliability, our dedicated editors meticulously review each submission. This process guarantees that the facts we share are not only fascinating but also credible. Trust in our commitment to quality and authenticity as you explore and learn with us.